
Overview
The Document service provides:
- REST interfaces
- Data CRUD operations
- URI search
- Indexes
- Aggregation
The Document service can store your data in one of the following ways:
The Document service can store data as a string, number, or nested data.
- By default, when your service reads the data, it receives raw data from storage and no conversion is performed.
- If you want to store or read data in a different way, such as to ensure data localization or store date values, then the service must send additional information about its data schema.
The Document service supports using a JSON schema to send your data. You can use a JSON schema to define the data format and document structure.
Let’s say you have a comic book store and you want to sell your comics over the Internet. In that case you need to store your documents in both managed and manageable manner.
To store your documents in a managed and manageable manner:
- Store the descriptions of your comics.
- Include the language in which the comic is published.
- Provide a simple list of comics with basic information.
- Allow searching comics by custom tags and provide sort options.
- Display the total number and the average price of comics that meet your customer's search query.
Here are some features of the Document service that can help you achieve the listed goals:
Store documents in organized manner
In the comic book store example, you want your comic book descriptions to be consistent. Each description should include, at minimum, the title, price, and availability of each comic. For this purpose, you need a schema that defines the title, price, and availability fields.
Multiple languages, multiple locations, no problem!
The best way to support comic sales in multiple languages is to use localized attributes. Most likely, a customer looking for comics in French, for example, does not want read comic descriptions in English or Spanish. You could set up your web site so that it allows customers to select their preferred language on your site's home page. To support this functionality with the Document service, set all of the home page display fields in your comics documents to localized. When your French-speaking customer selects French, all localized fields, such as Description, appear in the selected language. For example descriptions - when user chooses different language, you display the description in this language. What if you did not provide the description in the selected language? You can set a fallback, or default, language. For more information, see Operate on Object with Localized Attributes. Now that your site supports multiple languages, you realize that selling products internationally requires you to adjust prices and use different currencies. You can implement a logic that displays comic price in currencies based of the customer’s location, regardless of the language chosen. See the Data for more details about how to set up location-based currencies.
Simple list, complex details view You want your customers to see a simple list of comics that meets their search criteria and displays just a few important fields such as the title, a description preview, the release date, and the price. You also want to reduce the time it takes to display the list. To handle such a query response, explore projections: Perform a Projection. When a customer clicks on a particular position, you can display all available information stored for the comics using a simple GET request on a single document, with no worries about the response time.
Tags and sorting You want to further improve your customers' experience with a search option and support tags for your comics. Using tags and searching by keyword are probably the most convenient forms of searching, particularly when the user does not have a particular position or exact values in mind. You can read about how to use tags here: Tags. As your comic offerings grow in size, you want your customers to be able to sort their search results in the way that suits them best. To explore the sort options, see Search for Object sand Sort Search Result. To make sure your customers can retrieve the comics they want quickly, see Create an Index for Better Search Performance for important details about boosting search performance. Statistics If you want your customers to know how many comics meet their criteria as well as the average price, the Document service provides the capability to get aggregated data. See the Aggregation topic, so you don't have to reinvent the wheel when you set up your comic shop search functionality.
API Reference
/all
/all
Returns a list of all tenants for a given client.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
/all/statistics
Returns a list of all tenants for a given client with usage statistics.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
/all/statistics/total
Returns a document with detailed usage statistics for a given client.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
/{tenant}
Deprecated because of security vulnerability. The tenant string is the project's Identifier from the Builder. type: string
/{tenant}
Deprecated because of security vulnerability.
Deprecated because of security vulnerability.
Deprecated because of security vulnerability.
/{tenant}/{client}
Returns an internal representation of an application. Contains a list of existing types for this client and tenant.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Returns the same result as GET method but without body.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Deletes data and indexes for the specified tenant and client.
Security / Access Control:
To access this method, access token issued for client-owner must have hybris.document_admin and hybris.document_manage scopes, or access token issued for tenant must have hybris.document_manage scope to manage this resource.
/{tenant}/{client}/data/{type}
Returns the number of objects of this type. The 'q' query parameter enables you to count only objects fulfilling the criteria.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Returns all objects of this type which satisfy the criteria from the 'q' query parameter. If the 'q' query parameter is omitted, then the response contains all objects of this type.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Creates a new object of this type.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_manage scope to manage this resource.
Deletes data for the specified type.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_manage scope to manage this resource.
Bulk update of data which will be matched by a given query. All elements that match the query will be updated by data sent in payload.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_manage scope to manage this resource.
/{tenant}/{client}/data/{type}/{dataId}
Returns objects by objectId of this type. If the request does not contain the hybris-metaData header parameter with information about the attribute's localization or type conversions, then the response contains raw data. Cannot contain the following characters: /\ \"<>|?
*Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Returns the same result as GET method but without body.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Creates a new object of this type with a given objectId. If the request does not contain a hybris-metaData header parameter containing information about the attribute's localization, then the data is stored as raw data.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_manage scope to manage this resource.
Updates the object for objectId and type. If you want to update partially, use patch query parameter instead of partial, because it is deprecated.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_manage scope to manage this resource.
Deletes objects for objectId and type.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_manage scope to manage this resource.
/{tenant}/{client}/data/{type}/{dataId}/{attributeName}
Creates an element in the array. The attribute identified by name must be an array.
Security / Access Control:
To access this method, access token must be issued forclient and have hybris.document_manage scope to manage this resource.
Removes the given attribute from the document.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_manage scope to manage this resource.
/{tenant}/{client}/data/{type}/{dataId}/{attributeName}/{index}
Gets the element at this index from the array.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Returns the same result as GET method but without body.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Updates the element at this index in the array.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_manage scope to manage this resource.
Deletes the element at this index from the array.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_manage scope to manage this resource.
/{tenant}/{client}/aggr
/{tenant}/{client}/aggr/{type}
Returns the count of objects of this type. Additionally, objects can be filtered by a query.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Returns the result of aggregations for objects of this type. At least one of sum or avg query parameters is required. Additionally, the q parameter can be used to restrict the number of input objects.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
/{tenant}/{client}/indexes
/{tenant}/{client}/indexes/{type}
Returns all indexes created for a collection.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Returns the same result as GET method but without body.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Creates a new index.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_manage scope to manage this resource.
Deletes all indexes for this type.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_manage scope to manage this resource.
/{tenant}/{client}/indexes/{type}/{name}
Returns the index identified by the given name.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Returns the same result as GET method but without body.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_view scope to manage this resource.
Deletes an index by the given name.
Security / Access Control:
To access this method, access token must be issued for client and have hybris.document_manage scope to manage this resource.
/{tenant}/{client}/tags
/{tenant}/{client}/tags/{type}
/{tenant}/{client}/tags/{type}/{id}/{tagName}
Considerations
This section details the best practices to follow when using the Document service.
Use the Client Credentials token grant
The Document service requires a token obtained with the Client Credentials flow. This provides an additional level of security so that users who belong to a project but do not have Client Credentials cannot manipulate resources within the project. For more information about obtaining an access token and grants, see the OAuth2 service documentation.
Use data modeling characteristics for NoSQL storage
The Document service does not provide:
- Transactions spanned over more than one request
- Joins between objects
- Constraints typical for relational databases
- Data validation against used schema
These properties should be taken into consideration when designing the data model.
For more information about how to model your domain, see the MongoDB documentation. Some of the main concepts are:
- Data duplication and denormalization
- Embedding data (aggregated views)
Limit of simultaneously created indexes
Always try to plan your indexes in advance, to support your most time-critical queries from the outset. The Document service has a limit of five indexes, created simultaneously by a given client, and up to 20 indexes created at the same time per storage. You can minimize the risk of exceeding those limits by creating the index first. For small amounts of data the index creation process is short and don't block the index creation pool for long. If your request for index creation exceeds any of these limits, the service returns the 429 Too many requests response from the Document service. In that case you need to resend the request.
Restricted characters
When specifying your document, as in this example:
{
"key1": "value1",
"key2": "value2"
}
remember that you cannot use $, . nor null characters as field names (keys), as those are restricted by MongoDB.
schema field at the root level should be $schema, because there is logic, implemented in the service, that transforms it. However, at the subdocument level, the name of the schema field must not include $.Remove data but leave indexes
You can remove all data for a specified type while leaving all indexes unchanged. To do this, use a DELETE method on the /{tenant}/{client}/data/{type} resource and set the query parameter drop to false.
Use paging and limiting
The Document service uses paging by default, even if a request does not specify it. To support paging, the Document service uses a Links HTTP header to provide links to the:
- Current page:
rel=self - Previous page:
rel=prev(not present if the current page is the first page) - Next page:
rel=next(not present if the current page is the last page)
You can use the:
- pageSize parameter to specify how many results to return on one page. The default page size is 16.
- pageNumber parameter to point to a specific page of the returned results.
- sort parameter to sort your results to avoid situations in which one document is displayed on multiple pages or the document order changes when navigating from one page another.
This is an example request:
curl -G -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/comic?q=name:"Thorgal"+price:(>=10+AND+<=20)
+createdAt:>=2014-04-18&sort=createdAt:asc&pageNumber=2
Check the returned collection when searching to determine the number of returned objects
If you perform a GET request on a type's collection and the collection is empty, it does not return a status code of 404. Instead, it returns an empty list with a status code of 200.
Use the HEAD method if you only need the total number of queried objects
Perform a call on the {tenant}/{client}/data/{type} resource using the HEAD method with your specific query. The response includes a header with the total number of objects. For more information, see Search for objects and sort search results.
Limit the length of your query
Queries which are too long result in a 400 response from the service, with the following body:
{
"status": 400,
"message": "Request URI too long. Please minimize your query.",
"details": []
}
The query sends in the HATEOAS header. If it is too long, causing the total size of all headers to exceed 8 KB, the request fails. If the request fails for that reason, reduce the length of your query string and resend the request. For example, when you use the query to return multiple documents, you can use generic parameters instead of listing individual parameters such as IDs.
Security
The Document service is a container for your Documents. You control the data stored in the Document service, and only you know whether the document contains personal data and which data subject the data relates to. Therefore, to meet the data privacy requirements you must map documents containing personal data with corresponding data subjects, and implement a logic to serve data subject's requests related to its personal data, such as requests for information or deletion. To meet these goals, follow instructions provided in the Developer Guidelines for Data Privacy.
Multi tenancy
Core services provide you with multi multi-tenant model, which allows you to manage all your tenants' data in easy and convenient way. Your service is the client of core services, and it may contain as many tenants as you need. Without multi-tenancy, you would have to separate your tenants' data manually. In a multi multi-tenant model, you delegate tenant data separation to core services.
The Document service is a good example of a multi multi-tenant core service as it separates the data for services (clients) and within services for their tenants.
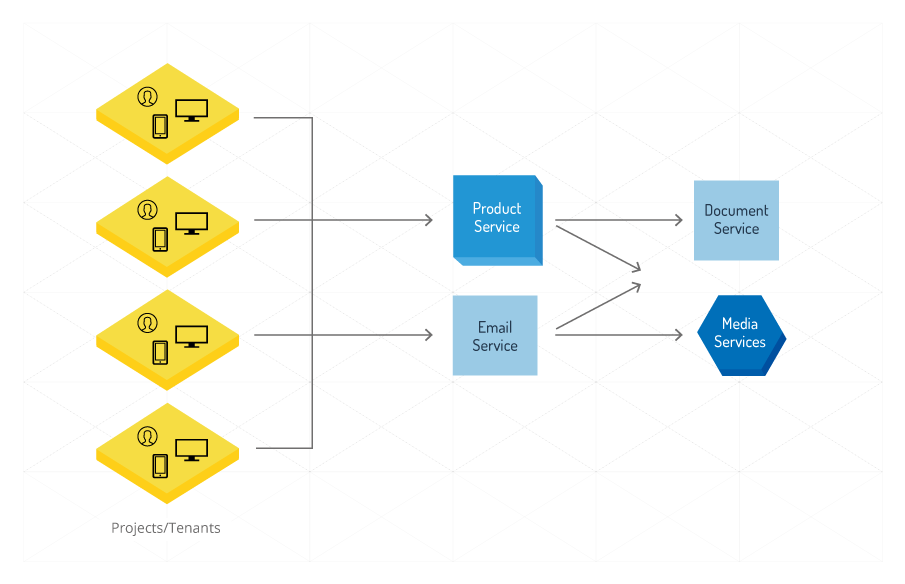
Example:
The Product and the Email services serve multiple tenants to store their documents and media files. Both the Product and the Email service are, in this case, clients of the Document and Media services. The diagram below illustrates those dependencies:
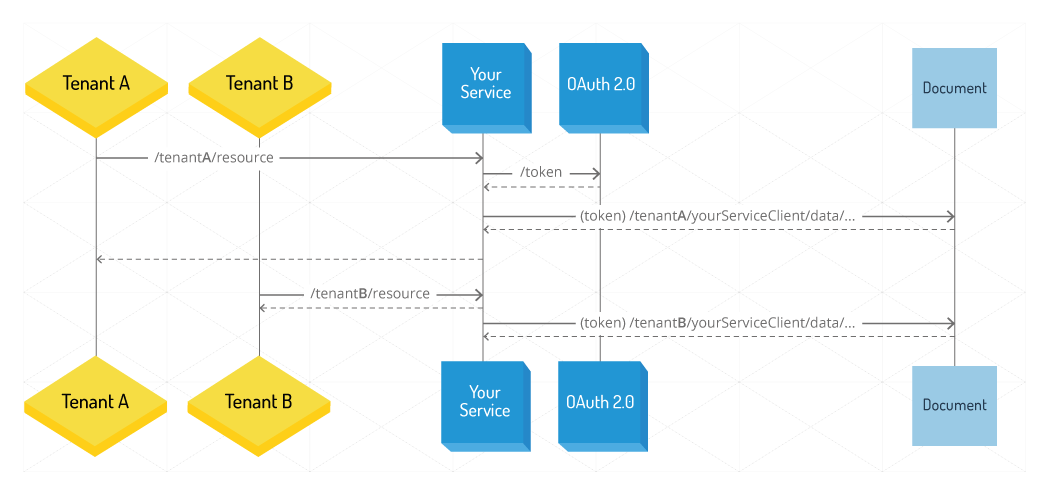
The Document service enables you to manage your service's tenants with a single access token issued for your service. Your service client is the owner of the data, and you don't have to issue new tokens with different hybris.tenant scopes. All you need to do is use your tenant identifier as the tenant in Document service path. In the following diagram, two tenants (A and B) call your service. Your service only has to get token once. The same token can then be used for all subsequent requests until the token the expires.
Schema
The Document service supports the use of JSON schemas. You can use a JSON schema to define a data format and the structure of the documents sent to the Document service. There can be different, separate schemas for each document. One advantage of using a schema is that you do not have to send data structure information in headers with every request as the schema allows you to store fields' values as a particular data type.
#/definitions reference to nested schemas in your documents' schemas, as it is not supported by the Document service. This restriction still allows you to save documents with nested schemas using a definitions reference, but they will not work.The Document service supports the following attributes:
- date -
"type": "date" - id -
{"$ref": "https://pattern.yaas.io/v1/schema-id.json"}- Download sample - createdAt -
{"$ref": "https://pattern.yaas.io/v1/schema-createdAt.json"}- Download sample - modifiedAt -
{"$ref": "https://pattern.yaas.io/v1/schema-modifiedAt.json"}- Download sample - localized -
{"$ref": "https://pattern.yaas.io/v1/schema-localized.json"}- Download sample - amount -
{"$ref": "https://pattern.yaas.io/v1/schema-amount.json"}- Download sample
SAP Hybris recommends that you store your schemas in the Schema service. If you choose to publish your schema on your own server instead, it must be accessible without authentication. To define a schema for your document, add the URI to the schema in the metadata attribute in the request body. For example:
{
"metadata" : {
"schema": "http://myserver.com/comicstore/comicSchema_v1.json"
}
}
Mixins
A mixin is a simple schema. It is defined by users of the Document service and contains additional attributes for a document. A collection of documents with schemas and mixins can be used to place additional attributes without making changes in the schema. The document, such as a product can have multiple mixins describing various attributes.
Mixins are optional, but they are a good way to keep the structure of the documents organized.
SAP Hybris recommends that you store your schemas in the Schema repository.
Data
Metadata
Storing and reading tips for the Document service are sent using a parameter in the header called hybris-metaData. This parameter contains information about the attribute's localization or date type. The hybris-metaData value structure is similar to this example:
attribute_name1:tip1;...;attribute_nameN:tipN
- The attribute_nameX field is the name of the attribute sent using JSON. If the attribute is nested, the name contains a nested path where each level is separated with a period (
.). - tipX is a tip about the data interpretation of field by Document service. It supports these tips:
- localized - Tip for localized data.
- date - Tip for date data.
- amount - Tip for localized currencies and prices.
- id - Tip for the document ID alias. For more information about how to use the hybris-metaData header for the ID alias, see Use alias on ID field when creating and searching.
Get the usage statistics for a client
The Document service allows you to get the usage statistics for a client.
List all tenants for a client
Send a GET request to the /all endpoint to list all tenants for a given client:
curl -H "Authorization: Bearer {ACCESS_TOKEN}" https://api.beta.yaas.io/hybris/document/v1/all
The successful response returns a 200 status code. An example JSON content in the response body looks similar to the following:
[
"firstTenant",
"secondTenant",
...
]
List all tenants for a given client with the usage statistics
Send a GET request to the /all/statistics endpoint to list all tenants for a given client with the usage statistics:
curl -H "Authorization: Bearer {ACCESS_TOKEN}" https://api.beta.yaas.io/hybris/document/v1/all/statistics
The successful response returns a 200 status code. An example JSON content in the response body looks similar to the following:
[
{
"timestamp": "2016-11-23T09:54:04.798+0000",
"client": "hybris.product",
"tenant": "firstTenant",
"typeCount": 4
},
{
"timestamp": "2016-11-23T09:54:04.798+0000",
"client": "hybris.product",
"tenant": "secondTenant",
"typeCount": 6
},
...
]
Note that in addition to the fields tenant and client, each document in the array contains the following fields:
timestamp- This is the timestamp when the report is generated.typeCount- This is the number of types for the given tenant.
/all/statistics. This is refreshed every hour.Get the usage statistics for a client
Send a GET request to the /all/statistics/total endpoint to acquire the usage statistics for a client:
curl -H "Authorization: Bearer {ACCESS_TOKEN}" https://api.beta.yaas.io/hybris/document/v1/all/statistics/total
The successful response returns a 200 status code. An example JSON content in the response body looks similar to the following:
{
"timestamp": "2016-11-23T09:54:04.798+0000",
"client": "hybris.product",
"tenantCount": 253,
"typeCount": 276,
"indexCount": 278,
"dataSizeBytes": 4445309608
}
The response contains the following fields:
timestamp- This is the timestamp when the report is generated.client- This is the client for which this report is generated.tenantCount- This is the number of tenants for the given client.typeCount- This is the number of types for the given client. It's a sum of all types for all tenants.indexCount- This is the overall number of indices for the given client. It's a sum of all indices for all tenants.dataSizeBytes- This is the overall data size in bytes, including types and indices.
/all/statistics/total. This is refreshed every hour.Create objects
You can create data objects using the /{tenant}/{client}/data/{type} endpoint by providing a proper application/json body. If your request does not include the hybris-metaData header parameter containing information about attribute localization, then the data is stored as raw data.
- If a request includes the hybris-metaData header parameter containing information about an attribute's localization and the Content-Language header parameter is NOT set, then you need to provide a language map in the body of the request.
- If a request includes the hybris-metaData header parameter containing information about an attribute's localization and the Content-Language is set, then the data is stored for the given language.
- Use either the Content-Language header or a language map in the body of the request. Do not use both.
- If a request includes the hybris-metaData header parameter containing information about an ID alias and an attribute with this name is in the request, then this attribute is interpreted as an ID in the database.
This is an example of a POST request without a hybris-metaData header:
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -H "Content-type: application/json" -X POST -d '{"kind":"History","name":"Thorgal"}' https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/comic
Store documents as a raw data
The Document service supports storing documents as a raw data. To use this functionality perform a POST request on the /{tenant}/{client}/data/{type} endpoint with rawwrite query parameter set to true. The body of your request must contain at least default metadata attributes, which are id, createdAt, modifiedAt, and version fields. Lack of those attributes results in 400 Bad Request response. The body is inserted to the database in the exact form you sent it with your request.
Please note that you cannot set both the rawwrite and patch query parameters to true, that results in 400 Bad Request.
Send and retrieve compressed data
When working with big data sets, you can send and receive encoded data to reduce response times and bandwidth usage. The Document service supports the GZIP format for content encoding. To send compressed data to the Document service, set the Content-Encoding header with the gzip value. To retrieve your data in the GZIP format, use the Accept-Encoding header with the gzip value. It is recommended that you use data encoding every time you send a large amount of data in the body of your request, as well as when you expect to receive a large data set in the response from the service.
Create objects with a specific ID
You can create data objects using the /{tenant}/{client}/data/{type}/{dataId} resource.
This is an example of a POST request with a specific dataId:
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -H "Content-type: application/json" -X POST -d '{"kind":"History","name":"Thorgal"}' https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/comic/1401
Do not check if the ID already exists before creating a new object
In this case, create an object with the ID you want it to have. If the ID already exists, an error is generated. For more information, see Perform simple CRUD operations.
Retrieve objects
You can retrieve specific objects using the /{tenant}/{client}/data/{type}/{dataId} resource to point to exactly one data object to be returned.
- If a request does not include a hybris-metaData header parameter containing information about an attribute's localization or type conversions, then the response contains raw data.
- If a request includes a hybris-metaData header parameter containing information about an attribute's localization and the hybris-languages header parameter value is
*, then the response contains data for all existing languages. - If a request includes a hybris-metaData header parameter containing information about an attribute's localization and Accept-Language is set, then the response contains data for the chosen language (with the given fallback).
- The value of the Accept-language parameter is case sensitive and should be exactly the same as Content-language parameter used to save localized attribute. For an example, you cannot search for attribute saved with Content-language
ENby setting Accept-language parameter toen. Those are two different fields. - If a request includes a hybris-metaData header parameter containing information about an ID alias, then the response contains an ID aliased by the defined name.
- If a request includes a hybris-metaData header parameter containing information about an ID alias with the same name as an attribute in the response, then the attribute in the response is overwritten by the ID.
The body of the response is a JSON object that contains all information for this specific object. For example:
{
"name": "Thorgal",
"metadata": {
"createdAt": "2014-07-25T09:01:51.145+0000",
"modifiedAt": "2014-07-25T09:01:51.145+0000",
"version": 1
},
"id": "53510b33f12ec86ab0bd0c90",
"title": "The Brand of the Exiles",
"kind": "History"
}
You can also retrieve a list of objects using the /{tenant}/{client}/data/{type} resource by providing query parameters for q.
- If the
qquery parameter is omitted, then the response contains all objects of this type. - If the totalCount query parameter is set to
true, then the response contains the hybris-Count header with the total number of objects of this type.
This is a sample request:
curl -G -i 'https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/comic/?q=rarity:uncommon'
The body of the response is an array of JSON objects matching the query parameters:
[
{
"cover": "hardcover",
"metadata": {
"createdAt": "2014-07-25T09:14:14.481+0000",
"modifiedAt": "2014-07-25T09:18:37.955+0000",
"version": 2
},
"price": 15.99,
"name": "Thorgal",
"id": "53d21fe66b8e4c58a577c509",
"title": "The Three Elders of Aran",
"rarity": "uncommon"
},
{
"cover": "paperback",
"condition": "good",
"metadata": {
"createdAt": "2014-07-25T09:15:05.035+0000",
"modifiedAt": "2014-07-25T09:18:37.955+0000",
"version": 2
},
"price": 15.99,
"name": "Thorgal",
"id": "53d220196b8e4c58a577c50b",
"title": "The Guardian of the Keys",
"rarity": "uncommon"
}
]
Update Objects
You can update an existing object with new information using the /{tenant}/{client}/data/{type}/{dataId} resource by providing the dataId.
- If a request does not include a hybris-metaData header parameter with information about an attribute's localization, then the data is stored as raw data.
- If a request includes a hybris-metaData header parameter containing information about an attribute's localization and the Content-Language header parameter value is not set, then the body of the request must contain a language map.
- If a request includes a hybris-metaData header parameter containing information about an attribute's localization and the Content-Language is set, then the data is stored for a given language.
- Use either the Content-Language header or a language map in the body of the request. Do not use both.
- If a URL includes the
upsert=trueparameter, then the object is created when updating non-existing objects. - If a URL includes the
upsert=falseparameter, then a status code of404is returned in the response when updating non-existing objects. - If the patch parameter is set to
true, a partial update is performed. Otherwise, a call results in a full object replacement.
This is an example of a PUT request:
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -H "Content-type: application/json" -X PUT -d '{"title": "Child of the Stars"}' 'https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/comic/53510b33f12ec86ab0bd0c90?patch=true'
You can also update many objects with a single request using the /{tenant}/{client}/data/{type} endpoint by providing query parameters for q. All elements matching the query are updated with the data sent in the payload.
This is an example of a PUT request that updates numerous objects:
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -H "Content-type: application/json" -X PUT -d '{"price": 18.99}' 'https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/comic/?q=rarity:uncommon'
In both cases, the response contains information about the status of the update:
{
"code": "200",
"status": "200",
"message": "Operation succeeded"
}
Use versioning (optimistic locking)
Use the optimistic locking feature provided by the Document service if your use case requires protection from parallel data modification, working with out-of-date data. For more information, see Perform versioning with optimistic locking.
/{tenant}/{client}/data/{type}/{dataId} resource, you can use a non-existing dataId. This operation generates these results:- If the URL contains the
upsert=trueparameter, then the new document with the given dataId is created. - If the URL contains the
upsert=falseparameter or this parameter is not given, then a status code of404is returned.
Attributes
You can add and remove additional attributes for objects using the /{tenant}/{client}/data/{type}/{dataId}/{attributeName} endpoint and providing the application/json body of the request that contains the attribute's values.
For example:
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -H "Content-type: application/json" -X POST -d '{"condition" : "mint"}' 'https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/comic/c001/condition'
Delete objects
There are several ways to delete objects.
- You can delete specific objects using the
/{tenant}/{client}/data/{type}/{dataId}resource by providing the dataId. This enables you to point to exactly one object to be deleted. - You can delete all objects for a specific type using the
/{tenant}/{client}/data/{type}resource. The delete operation can be narrowed by adding a query parameter forq. This enables you to delete all objects matching the query. - You can delete service data for a given tenant using the
/{tenant}/{client}/resource. A separate hybris.document_admin scope is required to access this method and the token has to be acquired for the client-owner (team).
This is an example of a DELETE request:
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -X DELETE https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/comic/53510b33f12ec86ab0bd0c90
Audit fields
Each object created in the Document service receives createdAt and modifiedAt fields by default. These fields contain information about when an object was created and when it was last modified.
For more information about using audit fields, see Use Aliases on Audit Fields.
Aggregation
The Document service offers sum and avg aggregates for numeric data stored inside documents and count to get the number of documents. You can also limit the number of documents used to calculate the aggregates by entering a query using the q parameter.
Some examples of use cases for this feature are:
- The number of products (filtered by manufacturer, color, and size)
- The average price of a product (filtered by category and manufacturer)
- The sum of products available in multiple warehouses
Retrieve aggregated data
To get aggregated data, use the /{tenant}/{client}/aggr/{type} resource.
The avg and sum parameters point to specific attributes of documents. You can use multiple attributes separated by commas for each aggregate. The count parameter takes a Boolean value. If set to true a number of documents will be included in a response.
Nested attributes
You can specify nested attributes providing the full path to the attribute where every level is separated by a dot. Because the dot is generally not allowed as a name of an attribute, it will be replaced with underscores in a response. For example, the value for spec.size.width will be returned as spec_size_width.
For example of an aggregation usage, see Get aggregated data.
Tags
The Document service enables you to add and remove tags for specific documents or a set of documents narrowed by a query. You can create tag arrays with different names and add them to existing objects.
Create tags for a specific document
To create tags for a specific document, use the /{tenant}/{client}/tags/{type}/{id}/{tagName} endpoint, where the id is a document ID (dataId), and tagName is the name of the tag array. Tag values must be provided using a tags parameter.
The POST request looks similar to this example:
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -X POST 'https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/tags/comic/c001/comicTags?tags=comic,paper'
Create tags for multiple documents
You can also add tags for multiple documents matching a query using the /{tenant}/{client}/tags/{type} resource by providing query parameters for q and the tag array name, followed by the tags in tags.
The POST request for this bulk operation looks similar to this example:
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -X POST 'https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/tags/comic?q=name:"Thorgal"&tags=genre:fantasy,adventure'
In both cases, the response is:
{
"code": "200",
"status": "200",
"message": "Operation succeeded"
}
Search documents using tags
To search documents using tag values, use the /{tenant}/{client}/data/{type} resource with query in the following form:
?q=tagAttribute1:all(value1,value2)+tagAttribute2:in(value1,value2)
The query is built according to the following rules:
- The
tagAttributeis a name of an array of tags. It reflects the{tagName}in the/{tenant}/{client}/tags/{type}/{id}/{tagName}resource. - Values in parentheses are comma-separated tag values.
- The
incriterion enables you to search documents in which the tag attribute contains any of the values in parentheses. - The
allcriterion enables you to search documents in which the tag attribute contains all of the values in parentheses. - The plus sign (
+) character is used because of URL encoding rules and takes the place of a space character that separates query conditions.
The GET request with query on tags looks similar to this example:
curl -I -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -X GET 'https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/comic?q=ComicTags:all(hardcover,reprint)'
Remove a specific tag array for a specific document
To remove tags from an array for a specific object, you can use the /{tenant}/{client}/tags/{type}/{id}/{tagName} resource, where id is a document ID (dataId) and tagName is the name of tag array. The tag values to be removed must be provided using a tags parameter.
The DELETE request looks similar to this example:
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -X DELETE 'https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/tags/comic/c001/comicTags?tags=comic,paper'
Remove tag values from tag arrays for multiple documents
To remove tags from an array for multiple documents, use the /{tenant}/{client}/tags/{type} resource and provide query parameters for q. The tag array name is followed by tags in tags.
The DELETE request looks similar to this example:
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -X DELETE 'https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/tags/comic?q=name:"Thorgal"&removeEmpty=false&tags=genre:fantasy,adventure'
false, the array of tags is not removed when all tags are deleted. The array remains empty. If removeEmpty parameter is set to true, the array is removed when last tag is deleted from it.Indexes
The Document service allows you to create indexes to significantly improve the search performance. For all time-critical queries, you should create thought indexes. Without appropriate indexes, a query scans all documents in a collection. When creating indexes, you should take into account a few considerations. This section will guide you through how to use indexes properly.
Start with queries
Understand how you want to search for your documents. Which attributes do you query? Do you plan to use sorting or projection? Based on this information, you can create a proper index for all of your queries. For example, to search by the country parameter, create an index that supports this case. If another query uses a different parameter or parameters, create an additional index to cover this case, too.
Create an index
You must create indexes for specific types. To create an index, use the /{tenant}/{client}/indexes/{type} resource by providing the application/json body of the request with the details of your index.
A definition of an index consists of two parts: keys (required), where you declare the fields to index, and options (optional), which contains additional configurations.
429 Too many requests response. You must wait for the ongoing index creation to finish and resend your request.{
"keys" : { ... },
"options" : { ... }
}
To create an index on audit field, such as createdAt or modifiedAt, use a full field name with a metadata prefix. Use a dot (.) for separation, as shown in the example:
{
"keys" : {
"metadata.createdAt" : 1
}
}
Keys
The keys subdocument consists of attribute-value pairs, where the attribute is the index key and the value defines the type of the index. The Document service supports two types: 1 for ascending indexes, and -1 for descending indexes.
{
"keys" : { "country" : 1, "city" : -1 }
}
As you can see, you can define more than one key. This creates a compound index, which supports queries on multiple attributes.
Options
The options subdocument allows you to provide additional configuration options for your index.
Options for all index types
Available options are:
| Options field name | Description | name | Allows you to assign a customized name to your index. |
|---|---|
| unique | Enforces the uniqueness of indexed fields |
| sparse | References only those documents that contain an indexed field |
Option field name
Use the name option to provide your own name for your index.
{
"keys" : { "country" : 1, "city" : -1 },
"options" : {
"name" : "CountryAndCityIndex"
}
}
If you don't specify the name of an index, the Document service generates a random name and you will receive the name in a response.
{
"name": "a2X1"
}
Option field unique
The unique option allows you to create unique indexes that enforce the uniqueness of indexed fields.
{
"keys" : { "country" : 1, "city" : -1 },
"options" : {
"name" : "CountryAndCityIndex",
"unique" : true
}
}
409 with the following message: Could not create unique index. Index contains fields with duplicated values.. To avoid this restriction applying to non-existent fields, create a unique index with a sparse option.Option field sparse
A sparse index contains entries only for documents that include the indexed field. Documents without the indexed field are skipped.
In some cases, it is useful to combine the unique and sparse options to reject duplicate values while ignoring documents that do not have the indexed field.
{
"keys" : { "country" : 1, "city" : -1 },
"options" : {
"name" : "CountryAndCityIndex",
"sparse" : true
}
}
Options for text indexes
| Options field name | Description |
|---|---|
| text index default language | Sets the default language for stop words and for rules used by the tokenizer and stemmer |
| text index weights | Sets the impact of the field in relation to other indexed fields |
You can find the additional description of options for text search indexes in the Full Text Search.
Option field default language
The default language for text indexes is English. You can set a different language as the default by including it in the options field for simple tokenization without stemming and stop words.
{
"keys" : { "title": "text", "description" : "text" },
"options": {
"default_language" : "none"
}
}
You can view a list of supported languages here.
Option field weights
You can set the weights for indexed fields under the options subdocument:
{
"keys": { "title": "text", "description" : "text" },
"options": {
"weights" : { "title" : 10, "description" : 2
}}
}
The preceding example indicates that when searching by the text index, the match for the title field has five times stronger impact than the match for the description field. You can combine an option to set the weights values for your fields with a scoreField query parameter to support your queries and provide the most relevant search results in your solution.
Compound index
A compound index is an index created for more than one field. Such an index supports queries that use multiple attributes.
To search by the two attributes, q=country:"Poland" age:>30, you would create a compound index as shown:
{
"keys" : { "country" : 1, "age" : 1 },
"options" : {
"name" : "CountryAndAgeIndex"
}
}
Compound indexes can support different queries. The index prefix concept presented in the MongoDB documentation can help you to better understand how it works. It states:
"Index prefixes are the beginning subsets of indexed fields."
For example, this sample compound index:
{
"keys" : { "country" : 1, "city" : 1, "age" : 1 }
}
has the following index prefixes:
{ country : 1 }{ country : 1, city : 1 }
You can use a compound index to support queries on the index prefixes. It means that Document service can use this index for queries on the following fields:
countrycountryandcitycountryandcityandage
It's important to understand this concept to avoid creating too many indexes. In the preceding example, we can have one index to support three types of queries instead of three separate indexes. The latter method is much more expensive, as each index consumes memory.
Sorting
Indexes support sorting. Sort operations backed by an index are usually faster.
For a single field index, you can sort the results in both ascending and descending order. For example, the index:
{
"keys" : { "country" : 1 }
}
allows sorting in both directions:
sort=country:ascsort=country:desc
For a compound index, you can sort by all the keys of the index or by a subset, but the keys must be listed in the same order as they appear in the index. For example, the compound index:
{
"keys" : { "country" : 1, "city" : 1 }
}
supports these sort methods:
sort=country:ascsort=country:asc,city:asc
The sort order must be the same as in the index definition for all attributes, or reversed for all attributes. The preceding example index supports the sort=country:desc,city:desc query but does not support the query sort=country:desc,city:asc.
View indexes
To retrieve a complete list of indexes for a specific type, you can use the /{tenant}/{client}/indexes/{type} resource. The list of indexes for the specified type is included in the response.
Remove indexes
You can use the DELETE method to delete indexes in two ways:
- Delete a specific index using the
/{tenant}/{client}/indexes/{type}/{name}resource. - Delete all indexes of a specific type using the
/{tenant}/{client}/indexes/{type}resource.
Best practices
To make the most of indexing, follow these best practices:
Create appropriate indexes for all of your time-critical queries.
Do not create an index for the
idfield. It already exists.Use compound indexes to support multiple queries. Compound indexes can be used by many different queries so you don't need to have a separate index for each one. This is very important as every index consumes memory and too many indexes can lead to worse performance.
Don't create too many indexes. All write operations must update every index created for a given type. This decreases the performance of write operations.
Use indexes that narrow down the results of your query. For example, if all of your documents include the
activefield with a value oftrue, then this field is not a good candidate for indexing.
Search
Table of contents
- Conditions
- Aliases for audit fields
- Searching documents using tags
- Searching documents using localized attributes
- Search performance
- Best practices
You can use the Document service to search for and return objects. This section describes how to use this functionality.
Conditions
in and all criteria
If an attribute can contain more than one distinct value, such as tags in the Document service, you can use in and all criteria for searching. The in criterion checks if any of the given values match any of the given attribute values. For example:
?q=ComicTags:in(hardcover,reprint)
The all criterion checks if all of the given values match the attribute values. For example:
?q=ComicTags:all(hardcover,reprint)
String values
To search documents using string values, always put the string value inside quotation marks "". For example:
?q=name:"Funky Koval"
To search for more than one string value for an attribute at a time, put the string values in parentheses () and separate them with commas ,. For example:
?q=title:("The+Guardian+of+the+Keys","The+Three+Elders+of+Aran","Child+of+the+Stars")
If a string value does not have any special characters or spaces, you can omit the quotation marks. For example:
?q=name:Thorgal
true, false, and null
The Document service converts the keywords true, false, and null to appropriate literals. Special literals true and false are used to search by fields of boolean type. In this case, you should use a query. For example:
?q=inStock:true
If a field contains string data, you can also search by these literals. For example:
?q=inStock:"false"
You can also check whether a value contains a null value. For example:
?q=publisher:null
exists and missing
You can search, not only by values, but also for the presence of an attribute using exists and missing. For example:
?q=name:exists
If you perform a query on a string data field, for example:
?q=message:"missing"
you'll get documents that contain the value missing in the message field, meaning this query won't test for the presence of the message field.
Equality
You can search for documents using a specified numeric value of the attribute. For example:
?q=price:20
If you search using numeric values, do not put them inside quotation marks because the values will be treated as string values.
The Document service also supports floating-point values if the value contains a period . character. For example:
?q=rating:9.5
Ranges
You can search for documents with a range of values for numeric values such as numbers or date and time. To specify the range, use the greater than >, greater than or equal to >=, less than <, or less than or equal to <= characters. For example:
?q=createdAt:>=2015-04-18
You can also combine ranges by putting them in parentheses () and using the AND operator. For example:
?q=price:(>=10+AND+<=20)
Aliases for audit fields
You can create aliases for audit fields in the Document service, such as createdAt or modifiedAt, by providing an alias in the metaData header when creating or updating a document. For example:
hybris-metaData : published:createdAt
You can use aliases for your query by providing information in the metaData header in addition to the query. For example:
hybris-metaData : published:createdAt
The query string looks like this example:
?q=published:>"2014-07-01T12:00:00Z"
For more information about using aliases on audit fields, see Use Aliases on Audit Fields.
- The value has a format of "yyyy-MM-dd". For example:
q=published:>"2000-10-20" - The attribute name is
createdAtormodifiedAt. For example:q=published:>"2014-07-01T12:00:00.000Z" - The attribute is an alias for
createdAtormodifiedAt, such asq=published:>"2014-07-01T12:00:00.000Z", and the request has a header of hybris-metaData : published:createdAt". - The attribute is a date type, such as
q=published:>"2014-07-01T12:00:00.000Z", and the request has a header of hybris-metaData : published:date.
Searching documents using tags
In this example, you search for a Thorgal comic using tags.
The tags must match all of following: "Thorgal", "hardcover", and "mint"
comicTags:all(Thorgal,hardcover,mint)The tags must match at least one of following: "collector's edition", "collectors", "signed", or "autograph"
comicAdditionalTags:in("collector's edition",collectors,signed,autograph)
This is how the query looks in a URI:
?q=comicTags:all(Thorgal,hardcover,mint)+comicAdditionalTags:in("collector's edition",collectors,signed,autograph)
- The
allcriterion enables you to search documents in which the tag attribute contains all of the values in parentheses. - The
incriterion enables you to search documents in which the tag attribute contains any of the values in parentheses. - The plus sign
+character is included because of URL encoding rules and takes the place of a space character that separates query conditions.
Searching documents using localized attributes
In this example, you search for a comic with the localized attribute title with a value in English of The Archers. As localized attributes are nested, you need to provide the language value after the ., as shown in this example:
?q=title.en:"The Archers"
- If a request does not include a hybris-metaData header parameter containing information about an attribute's localization or type conversions, then the response contains raw data.
- If a request includes a hybris-metaData header parameter containing information about an attribute's localization and the hybris-languages header parameter value is
*, then the response contains data for all existing languages. - If a request includes a hybris-metaData header parameter containing information about an attribute's localization and Accept-Language is set, then the response contains data for the chosen language (with the given fallback).
- The value of the Accept-language parameter is case sensitive and should be exactly the same as Content-language parameter used to save localized attribute. For an example, you cannot search for attribute saved with Content-language
ENby setting Accept-language parameter toen. Those are two different fields. - If you want to sort the response by localized fields you must provide a language:
?sort=name.pl. - If you sort the response by a localized field and your request includes a hybris-metaData header parameter containing information about an attribute's localization and the language is not provided, then
400 Bad Requestresponse is returned.
Search Performance
The Document service is protected against long-running queries. Queries that take too long (more than one second) are timed out by the service. To avoid such situations and to improve the performance of your queries, you should comply with the following rules:
Indexes
Create indexes to support your queries. For more information on indexes, see Indexes.
Paging
Use paging to improve the performance of your queries and to reduce the amount of data returned from the Document service.
Page size
Use small page sizes. Queries with huge page sizes take longer to complete and as a result may end up timing out.
Page number
Avoid big page numbers. Using big page numbers can be very expensive, because it requires the database to walk from the beginning of the collection or index. The query is executed more slowly for each subsequent page. The recommended method is to use range-based pagination based on your use case, because it can better utilize your indexes.
Let's use a more specific example. Let's assume that we have 100,000 documents, created in a single month. We can query for all documents from this month and read them, page by page. Unfortunately, in this approach, subsequent queries will be slower and slower as they all require walking from the beginning of the whole set. A better solution is to read documents by day ranges. Every range will have fewer documents to go through and will use indexes more effectively. If you still want a Document service to return all documents of a given type, please see subsequent section, which describes streaming functionality.
Streaming large result sets
You can gather an entire result set in a single request. For queries performed on the /{tenant}/{client}/data/{type} endpoint, set the fetchAll query parameter to true to stream the response using Chunked transfer encoding. The streaming mechanism in the Document service improves the efficiency of your queries by reducing response times and the consumption of resources for large results sets.
For example, suppose you request all the documents created in the past month that have the type invoice, without streaming the results. If the result includes 10,000 documents, iterating it using paging, which is not recommended, can result in definitely slower responses with each request. When you set the fetchAll parameter to true, you can send one request to get the entire type, which the service streams back in HTTP chunks.
fetchAll query parameter is set to true, you cannot provide pageNumber and/or pageSize query parameters as this results in 400 Bad request response from the Document service.The streamed response does not contain
totalCount (even if total count parameter was set to true within the initial request). If you need a number of documents that are returned, you must handle this logic on your side.]. If using fetchAll and your response ends with any other character, it indicates that the stream has been corrupted and you may want to resend your request.Projection
Use projection to read only the attributes that you require. Projection speeds up the query and reduces the amount of data returned by the service.
Primitive types
Wherever possible, use primitive types (numbers and dates) instead of strings. Queries on numbers, as compared to queries on strings, can take up to four times less time. Be especially careful with attributes containing dates. If you don't use a schema, a mixin, or a hybris-metaData header, attributes that contain dates are stored as strings.
Best practices
Use the following best practices to maximize the efficiency of your queries.
Use UTC time and date for time-related queries
The Document service uses combined date and time in the UTC ISO standard format built as <date>T<time>, for example, 2014-07-25T09:15:05.035+0000.
The standard time zone for the Document service is GMT.
Encode and escape reserved characters
Queries used in the Document service are passed in a URI. A query component begins with a question mark ? character and ends with a number sign # character on the end of the URI.
Some characters, such as spaces, are not available for "raw use" in URLs and must be escaped or encoded using percent-encoding.
String values must be inside quotation " " marks. If you have quotation marks inside your string values, you must escape them using the backslash \character, as in, ?q=name:"Thorgal \"Child of the Stars\" Aegirsson".
Combine conditions inside your query
To combine more than one condition inside your query, use the plus sign + character between conditions instead of a space.
To search in a range of values or search using specific values, put the query in parentheses (). For example:
price:(>=10+AND+<=20)`
title:("The+Guardian+of+the+Keys","The+Three+Elders+of+Aran","Child+of+the+Stars")
title:("The+Guardian+of+the+Keys","The+Three+Elders+of+Aran","Child+of+the+Stars"), the comma , character is used as an OR operator.400 response from the service, with the following message in the body: Request URI too long. Please minimize your query. If that happens, limit the length of your query string and resend the request.Full text search
The Document service supports full text search, which means you can search for text in string fields in documents.
The Document service full text search feature supports:
- case-sensitive and case-insensitive search
- diacritic-sensitive and diacritic-insensitive searches to recognize or ignore text with accent marks
- searching in a specified language
- applying weights to text fields
- scoring search results
Assumption
This topic describes how to use full text search in the Document service based on the following example data.
[
{
"title" : "Functional programming in Scala",
"description" : "This is book about functional programming using Scala language",
"price" : 10,
"metadata" : {
"createdAt" : "2016-12-07T14:04:03.637+0000",
"modifiedAt" : "2016-12-07T14:04:03.637+0000",
"version" : 1
},
"id" : "584816d34131211355867871"
},
{
"title" : "Functional programming in JavaScript",
"description" : "This is book about functional programming using JavaScript",
"price" : 5,
"metadata" : {
"createdAt" : "2016-12-07T14:04:21.358+0000",
"modifiedAt" : "2016-12-07T14:04:21.358+0000",
"version" : 1
},
"id" : "584816e54131211355867872"
},
{
"title" : "Cooking for fun",
"description" : "Book about cooking",
"price" : 15,
"metadata" : {
"createdAt" : "2016-12-07T14:05:05.620+0000",
"modifiedAt" : "2016-12-07T14:05:05.620+0000",
"version" : 1
},
"id" : "584817114131211355867873"
},
{
"title" : "Fishing",
"description" : "Fishing for masters",
"price" : 20,
"metadata" : {
"createdAt" : "2016-12-07T14:10:02.447+0000",
"modifiedAt" : "2016-12-07T14:10:02.447+0000",
"version" : 1
},
"id" : "5848183a4131211355867874"
}
]
Create a text index
Before using text search, create a text index. To create an index, send the application/json body of the request with the details of your index to the /{tenant}/{client}/indexes/{type} resource.
The definition of a text index consists of two parts:
- keys (required), where you declare the fields to index
- options (optional) where you define an additional configuration, such as name or default_language
{
"keys" : {
"title": "text",
"description" : "text"
},
"options": {
"name" : "myTextIndex"
}
}
Example:
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -H "Content-type: application/json" -X
POST -d '{"keys":{"title": "text","description" : "text"},"options": {"name":"myTextIndex"}}}' https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/indexes/books
This call creates a text index on 2 fields, title and description.
When you perform a GET request to check the text index details:
curl -X GET -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" "https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/framefrog.mycomicsshop/indexes/comic"
The response looks similar to the example shown:
[
{
"keys": {
"_id": 1
},
"options": {
"name": "_id_"
}
},
{
"keys": {
"$text": true
},
"options": {
"name": "myTextIndex",
"default_language": "english",
"weights": {
"description": 1,
"title": 1
}
}
}
]
Text search
To search for documents using the full text search feature, use the text query parameter.
Example
curl -X GET -H "Authorization: Bearer 021-08d6c686-6fc1-4149-aa5b-1a05a42f40d1" "https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/books?text=JavaScript%20Scala"
The request returns two documents:
[
{
"title": "Functional programming in Scala",
"description": "This is book about functional programming using Scala language",
"price" : 10,
"metadata": {
"createdAt": "2016-12-07T14:04:03.637+0000",
"modifiedAt": "2016-12-07T14:04:03.637+0000",
"version": 1
},
"id": "584816d34131211355867871"
},
{
"title": "Functional programming in JavaScript",
"description": "This is book about functional programming using JavaScript",
"price" : 5,
"metadata": {
"createdAt": "2016-12-07T14:04:21.358+0000",
"modifiedAt": "2016-12-07T14:04:21.358+0000",
"version": 1
},
"id": "584816e54131211355867872"
}
]
You can also use text search in combination with a regular query. To search in this way, provide both the text and q query parameters.
curl -X GET -H "Authorization: Bearer 021-08d6c686-6fc1-4149-aa5b-1a05a42f40d1" "https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/books?q=price:5&text=JavaScript%20Scala"
The request returns only one document, the book about JavaScript:
[
{
"title" : "Functional programming in JavaScript",
"description" : "This is book about functional programming using JavaScript",
"price" : 5,
"metadata" : {
"version" : 2,
"createdAt" : "2016-12-08T07:37:27.838+0000",
"modifiedAt" : "2016-12-08T07:38:42.947+0000"
},
"id" : "584816e54131211355867872"
}
]
Text search with additional parameters
When using text search, you can also provide additional parameters to support case-sensitive search, language-specific text search, and diacritic-sensitive text search.
Case-sensitive search
There is an additional caseSensitive query parameter. If set to true, then the text search is case sensitive. The default value is false.
Example:
curl -X GET -H "Authorization: Bearer 021-08d6c686-6fc1-4149-aa5b-1a05a42f40d1" "https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/books?text=Book&caseSensitive=true"
This search returns only one document:
[
{
"title" : "Cooking for fun",
"description" : "Book about cooking",
"price" : 15,
"metadata" : {
"version" : 1,
"createdAt" : "2016-12-08T07:37:40.135+0000",
"modifiedAt" : "2016-12-08T07:37:40.135+0000"
},
"id" : "584817114131211355867873"
}
]
Language-specific text search
The language query parameter determines the list of stop words for language-specific searches, as well as the rules for the stemmer and tokenizer functions. Stop words are common words that the system can ignore, the stemmer identifies the root form of words, and the tokenizer identifies phrases and meaningful terms within text strings.
Diacritic text search
The diacriticSensitive query parameter is a Boolean flag that enables or disables a diacritic-sensitive search. Use the parameter to recognize or ignore the accent marks used in various languages during a full text search.
Text search with document score
The text search feature allows you to add a score to each returned document. The score represents the relevance of a document to a given text search query. To add a score to the results, provide an additional query parameter, scoreField, with the name of the field to add to each document.
Because there is no restriction on the document scheme, you can specify the score field name. Changing the name avoids overriding your fields with the new score field that the full text search feature adds.
For example, specify the query parameter scoreField=rank to add a field called rank to every document, along with the document score.
Example
curl -X GET -H "Authorization: Bearer 021-08d6c686-6fc1-4149-aa5b-1a05a42f40d1" "https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/books?text=Book&scoreField=rank"
The request returns the following documents:
[
{
"title" : "Functional programming in Scala",
"description" : "This is book about functional programming using Scala language",
"price" : 10,
"metadata" : {
"version" : 1,
"createdAt" : "2016-12-08T07:37:17.534+0000",
"modifiedAt" : "2016-12-08T07:37:17.534+0000"
},
"rank" : 0.5833333333333334,
"id" : "584816d34131211355867871"
},
{
"title" : "Functional programming in JavaScript",
"description" : "This is book about functional programming using JavaScript",
"price" : 5,
"metadata" : {
"version" : 2,
"createdAt" : "2016-12-08T07:37:27.838+0000",
"modifiedAt" : "2016-12-08T07:38:42.947+0000"
},
"rank" : 0.6,
"id" : "584816e54131211355867872"
},
{
"title" : "Cooking for fun",
"description" : "Book about cooking",
"price" : 15,
"metadata" : {
"version" : 1,
"createdAt" : "2016-12-08T07:37:40.135+0000",
"modifiedAt" : "2016-12-08T07:37:40.135+0000"
},
"rank" : 0.75,
"id" : "584817114131211355867873"
}
]
Sort results by search score
By default, the service does not sort the text search results by relevance. Use the score feature to sort by relevance. To sort results by score, add the scoreField and sort query parameters to your request. Specify the field that contains the score in the scoreField parameter.
Unlike typical field sorting, you can sort the scoreField in ascending order only.
Example
curl -X GET -H "Authorization: Bearer 021-08d6c686-6fc1-4149-aa5b-1a05a42f40d1" "https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/data/books?text=Book&scoreField=rank&sort=rank:asc"
The search returns sorted results:
[
{
"title" : "Cooking for fun",
"description" : "Book about cooking",
"price" : 15,
"metadata" : {
"version" : 1,
"createdAt" : "2016-12-08T07:37:40.135+0000",
"modifiedAt" : "2016-12-08T07:37:40.135+0000"
},
"rank" : 0.75,
"id" : "584817114131211355867873"
},
{
"title" : "Functional programming in JavaScript",
"description" : "This is book about functional programming using JavaScript",
"price" : 5,
"metadata" : {
"version" : 2,
"createdAt" : "2016-12-08T07:37:27.838+0000",
"modifiedAt" : "2016-12-08T07:38:42.947+0000"
},
"rank" : 0.6,
"id" : "584816e54131211355867872"
},
{
"title" : "Functional programming in Scala",
"description" : "This is book about functional programming using Scala language",
"price" : 10,
"metadata" : {
"version" : 1,
"createdAt" : "2016-12-08T07:37:17.534+0000",
"modifiedAt" : "2016-12-08T07:37:17.534+0000"
},
"rank" : 0.5833333333333334,
"id" : "584816d34131211355867871"
}
]
Create a text index with a specified default language
You can create a text index with a default language by providing the body content as shown:
{
"keys" : {
"title": "text",
"description" : "text"
},
"options": {
"name" : "myTextIndex",
"default_language": "german"
}
}
To learn more about the available options for your indexes, see the Options subsection under Create an index, which describes the options and recommendations for usage in detail.
Example
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -H "Content-type: application/json" -X POST -d '{"keys":{"title": "text","description" : "text"},"options": {"name":"myTextIndex", "default_language": "german"}}}' https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/indexes/books
For a list of available languages, refer to the MongoDB documentation, Text Search Languages.
Create a text index on all document fields
You can also create a text index on all fields in your documents. Provide a wildcard field name in the keys section of your request called $all.
{
"keys" : {
"$all" : "text"
},
"options": {
"name" : "myTextIndex",
"default_language" : "german"
}
}
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -H "Content-type: application/json" -X POST -d '{"keys":{"$all": "text"},"options": {"name":"myTextIndex", "default_language": "german"}}}' https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/indexes/books
Create a compound index with text
You can create a compound index that includes text fields.
{
"keys" : {
"price" : 1,
"title" : "text"
},
"options": {
"name" : "myTextIndex",
"default_language" : "german"
}
}
curl -i -H "Authorization: Bearer 081-3f1219c6-35wf-4863-87b6-5fccf07e09ba" -H "Content-type: application/json" -X POST -d '{"keys":{"price": 1, "title" : "text"},"options": {"name":"myTextIndex", "default_language": "german"}}}' https://api.beta.yaas.io/hybris/document/v1/mycomicsshop/myorg.stock/indexes/books
For compound indices, provide both text and query parameters in the search request.
Caching
Basic information
The Document service supports HTTP caching headers to significantly reduce:
- Response times.
- Bandwidth by not sending the same documents again.
- Processing resources of the service and the underlying MongoDB database.
The Document service uses ETag (entity tag) headers for cache validation.
When you query a type or fetch a single document, the service calculates an ETag. The ETag mechanism is based on the last modification timestamp of a type. If any document was added, deleted, or modified in a type since the last request, the ETag is invalidated and the service returns a new ETag with the response code 200, along with the payload. Otherwise, the service returns 304 without a payload, and informs you that the type was not modified. ETag works in the same way when fetching a single document as well as whole types.
Example
Step 1: The client issues a GET request in order to fetch a single document or an array of documents.
Request
GET /mycomicsshop/myorg.stock/data/comic HTTP/1.1
User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36
Host: https://api.beta.yaas.io/hybris/document/v1
Accept: */*
Step 2: The Document service responds with the document (or an array of documents) with additional ETag and Cache-Control headers. It calculates the value of the entity tag based on response payload. The value of the entity tag is unique.
Response
HTTP/1.1 200 OK
Date: Thu, 11 Jun 2015 09:33:58 GMT
Content-Type: application/json
Content-Length: 228
ETag: "1472652915"
Cache-Control: private, max-age=31536000
[ {
"kind" : "History",
"name" : "Thorgal",
"metadata" : {
"createdAt" : "2015-06-11T09:33:24.462+0000",
"modifiedAt" : "2015-06-11T09:33:24.462+0000",
"version" : 1
},
"id" : "557955e4da08b4f25a0a3f18"
} ]
Step 3: After a while, the client wants to get the same content again, so it makes the same GET request one more time. This time it adds the If-None-Match header, the value of which is the entity tag received from the previous response.
Request
GET /mycomicsshop/myorg.stock/data/comic HTTP/1.1
User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36
Host: https://api.beta.yaas.io/hybris/document/v1
Accept: */*
If-None-Match: "1472652915"
Step 4: The Document service calculates the hash for the payload and compares it to the one from the If-None-Match header from the client's request. If both hashes are equal, the type was not modified and the Document service responds with a status code of 304 (Not Modified) without a payload.
Response
HTTP/1.1 304 Not Modified
Date: Thu, 11 Jun 2015 09:33:58 GMT
ETag: "1472652915"
Cache-Control: private, max-age=31536000
Otherwise, if the document modification occurred within the type and the entity tag differs, it responds with a status code of 200 (OK) with a payload containing the newest version. It also adds the ETag header with a newly calculated hash.
Response
HTTP/1.1 200 OK
Date: Thu, 11 Jun 2015 09:34:01 GMT
Content-Type: application/json
Content-Length: 237
ETag: "1472829315"
Cache-Control: private, no-cache
[ {
"kind" : "History",
"name" : "Thorgal modified",
"metadata" : {
"createdAt" : "2015-06-11T09:33:24.462+0000",
"modifiedAt" : "2015-06-11T09:33:59.462+0000",
"version" : 2
},
"id" : "557955e4da08b4f25a0a3f18"
} ]
In cases similar to the example shown, you should update the ETag. Otherwise, when an ETag from the request does not match the current ETag for the type, all subsequent requests return the 200 (OK) response, along with a payload.
This diagram illustrates the aforementioned process.
Naming conventions
The Document service ensures that the given parameters are valid using the following rules:
- Tenant - Must be the same as your Project Identifier from the Builder
- Cannot be null or empty
- Must have 1-36 characters
- Cannot contain the following characters:
/\. "*<>:|?
- Client - An ID of a caller
- Cannot be null or empty
- Must have 6-49 characters
- Cannot contain non-alphanumeric characters other than
. - It is built as a combination of
<project_id>and<client_name>separated by a period (.) <project_id>must have 3-16 characters<client_name>must have 2-32 characters
- Type
- Cannot be null or empty
- Must have 1-36 characters
- Cannot contain the following characters:
/\. "*<>:|?
- dataId
- Cannot be null or empty
- Cannot contain the following characters:
/\ "*<>|?
Available optimisations to boost your Document service experience
This section describes tips and tricks for improving your experience with the Document service by enhancing performance, reducing resource consumption, and organizing your data.
- When you work with organized data, you can rely on its structure and find exactly the data you need. There are two ways to keep your content well-organized: Use schemas stored in the Schema service, or use mixins, defined in the Document service.
- Because schemas in the Schema service are immutable, mixins are a good way to add structure to additional attributes. You can also combine mixins so that documents that contain different attributes can use the same structure of a common attributes. To learn more about schemas, see the Schema topic. To find out more about mixins, visit the Mixins section.
- You can make your queries less time- and resource-consuming by using one of these options for improving search performance:
- Paging
- Streaming, which is more effective for operations on big sets of documents
- Content encoding
To improve your search performance, read the Search performance topic. You can also find valuable tips regarding projection and primitive types usage.
- Creating indexes is an important improvement for all time-critical queries. However, creating indexes is effective only when indexes are thorough, so take your time to read through the Indexes topic. Consider which queries you would like to support with indexing, and how to build the indexes.
- To significantly reduce bandwidth and processing resources, as well as response times, see the Caching topic, which elaborates on E-Tag support in the Document service.
- Use aggregates such as
sumorcountto quickly receive information without handling the data on the client side. See the Aggregation topic for more information. - Whenever possible, read and write data using GZIP encoding. For
GETrequests set the Accept-Encoding header togzipto receive compressed data and forPUTandPOSTrequests set the Content-Encoding header togzipand provide compressed body. Transferring compressed data significantly reduces response times and the bandwidth used. - You can boost performance and lower your bill by combining two or more of the aforementioned tips.
Here are some example scenarios that use these improvements for document organization, as well as for boosting search performance and reducing costs.
Document organization improvement
You can improve the overall organization of your documents by using schemas with mixins or separate mixins.
Schema and mixin or mixins
In this scenario, you plan to create lots of documents that have a particular structure as well as a few documents that have additional attributes.
First, create a schema in the Schema service that corresponds to the structure of most of your documents. To provide structure for the few documents with extra attributes, create a mixin for the additional attributes. You can also create a separate mixin for each different attribute, so you can combine and mix them according to your needs.
Performance boosters and cost savers
You can enhance the performance of your searches using the following methods.
q query + tags + paging + projection + primitive types
Build your query, narrowing the search to include, for example, documents that contain specific tags, as well as a date range. You can use projection if you only need the response to return some fields (for example, product name and price). The price is stored as a number, so it doesn't needlessly slow down the query. Set the pageSize for your request (the lower the better) and provide the pageNumber to be returned.
q query + fetchAll
The most efficient way to get a big data set is to send the fetchAll parameter, set to true and the Accept-Encoding header set to gzip, along with the GET request. You can further speed up the process by narrowing the results with a q query parameter. Using this approach, you can receive an entire set of documents in a single response, from a single request. The service delivers the data set to you in a compressed gzip format, which significantly improves performance. If you do not use the q query parameter to narrow your requests for very large documents sets of a given type, the service does not return the full data set in response.
Aggregation
Suppose you need to know how many documents of a given type you have, and the average value of two of the attributes. You can accomplish this most efficiently by sending a request with the avg parameter pointing to the specified attributes, and the count parameter set to true. With this approach, you receive your response almost instantly and do not need to worry about the logic for both operations.
Introduction To Tutorials
The Document service API tutorials are based on the following scenario:
- You have a shop that sells comics.
- Comic books are identified by a type named comic to differentiate them from other types of books.
- You are creating a comic called Thorgal.
{tenant} with your Project Identifier and {client} with your YaaS Client Identifier. Both values can be obtained from Projects > {My Project} > Clients > {My client} in the Builder. For more details, see the Authorization section of the Overview.Do not use the Document service as MongoDB over REST
Even though the Document service is implemented with MongoDB as storage:
- Do not rely on MongoDB functions.
- Do not use naming conventions typical for MongoDB.
- Do not use any restricted characters as field names in subdocuments.
- Use only Document service conventions.
Perform Simple CRUD Operations
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create an API client for the Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
Create a simple object
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic.
- Required:
- Response:
- Status code: 201
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
'kind': 'History',
'name': 'Thorgal'
},
{
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj.body
To make calls simpler and code cleaner, assign Id of returned object to a variable.
id = comic_obj.body.id;
id
Retrieve an object
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic - dataId: The Id of an object.
- Required:
- Response:
- Status code: 200
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_obj.body
Retrieve all objects of a given type
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/ - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic
- Required:
- Response:
- Status code: 200
get_all = documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_all.body
Update an object with additional information
Perform a partial update on the object:
- Method: PUT
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic. - dataId: The ID of an object.
- Required:
Query Parameters:
- patch:
true
- patch:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).put({
'title': 'Child of the Stars'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {
'patch' : true
}
})
comic_obj.body
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic. - dataId: The ID of an object.
- Required:
Verify the object update
Get the object to make sure that it was updated. With the exception of the new attribute, the modifiedAt date information is also updated.
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_obj.body
Update an object with new information
Now perform a full replace of the object.
- Method: PUT
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic. - dataId: The ID of an object.
- Required:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).put({
'name': 'Thorgal',
'title': 'The Brand of the Exiles',
'kind': 'History'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj.body
Verify the information replacement
With the exception of the new attribute, the modifiedAt and createdAt date information is also updated.
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic. - dataId: The ID of an object.
- Required:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_obj.body
Delete an attribute from an object
- Method: DELETE
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId}/{attributeName} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic. - dataId: The ID of an object.
- attributeName: The name of an attribute. In this example, it is
name.
- Required:
remove = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).attributeName('name').delete(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
}
})
Delete an object
- Method: DELETE
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId}
remove = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).delete(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
}
})
Verify the object delete
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic. - dataId: The ID of an object.
- Required:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_obj.body
Create a simple object with a custom ID
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic. - dataId: The ID of an object. In this example, it is
sampleId.
- Required:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId('sampleId').post({
"kind": "History",
"name": "Thorgal"
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj.body
documentService.tenant(tenant).client(client).data.type('comic').dataId('sampleId').delete(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
}
})
comic_obj.body
Use Date and Time Attributes When Creating and Searching
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
Create an object with one date/time attribute
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic.
- Required:
- Headers:
- hybris-metaData:
releaseDate:date
- hybris-metaData:
- Response:
- Status code: 201
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'Child of the Stars',
'releaseDate': '1986-05-13T12:00:00.000Z'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metaData' : 'releaseDate:date'
}
})
comic_obj.body
The date should be provided in ISO standard format.
Retrieve an object with a query on the date/time attribute
200.Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic.
- Required:
- Headers:
- hybris-metaData:
releaseDate:date
- hybris-metaData:
- Query Parameters:
- q:
releaseDate:(>=1986-05-13 AND <1986-05-14)
- q:
- Response:
- Status code: 200
To get an object with a specific date, you must combine a query as shown in the example. You cannot use releaseDate:=1986-05-13.
get_obj = documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metaData' : 'releaseDate:date'
},
query: {
'q' : "releaseDate:(>=1986-05-13 AND <1986-05-14)"
}
})
get_obj.body
Use Alias on an ID Field When Creating and Searching
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
Create an object with an alias on the ID field
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic.
- Required:
- Headers:
- hybris-metaData:
comicId:id
- hybris-metaData:
- Response:
- Status code: 201
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
'kind': 'History',
'name': 'Thorgal',
'comicId': 'C01H02'
},
{
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metaData' : 'comicId:id'
}
})
comic_obj.body
Retrieve an object with an alias on the ID field using query parameters
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic.
- Required:
- Headers:
- hybris-metaData:
comicId:id
- hybris-metaData:
- Query Parameters:
- q:
comicId:"C01H02"
- q:
- Response:
- Status code: 200
get_obj = documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metaData' : 'comicId:id'
},
query: {
'q' : "comicId:C01H02"
}
})
get_obj.body
Retrieve all objects with an alias on the ID field
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic.
- Required:
- Headers:
- hybris-metaData:
comicId:id
- hybris-metaData:
- Response:
- Status code: 200
get_obj = documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metaData' : 'comicId:id'
}
})
get_obj.body
Request
- Method: HEAD
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic.
- Required:
- Headers:
- hybris-metaData:
comicId:id
- hybris-metaData:
- Query Parameters:
- q
comicId:(C01H02, C01H03)
- q
- Response:
- Status code: 200
count = documentService.tenant(tenant).client(client).data.type('comic').head(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metaData' : 'comicId:id'
},
query: {
'q' : "comicId:(C01H02, C01H03)"
}
})
count.headers
Use Aliases on Audit Fields
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
In the Document service, you can map different naming for the audit fields createdAt and modifiedAt. This can be done using metadata or a schema.
Prerequisites
There are two schemas used in this tutorial. You can create schemas based on the these examples and publish them on a server of your choice or in the Schema service:
Mapping audit fields using metadata
Create a document with nested audit fields and aliases
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
Headers:
- hybris-metadata:
timeDetails.when_created:createdAt;timeDetails.when_changed:modifiedAt
- hybris-metadata:
- Response:
- Status code:
201
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'Children of the stars'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metadata' : 'timeDetails.when_created:createdAt;timeDetails.when_changed:modifiedAt'
}
})
comic_obj.body
To make calls simpler and code cleaner, assign Id of returned object to a variable.
id = comic_obj.body.id;
id
Retrieve a document
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Headers:
- hybris-metadata:
timeDetails.when_created:createdAt;timeDetails.when_changed:modifiedAt
- hybris-metadata:
- Response:
- Status code:
200
- Status code:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metadata' : 'timeDetails.when_created:createdAt;timeDetails.when_changed:modifiedAt'
}
})
get_obj.body
Mapping audit fields using a schema
Create a document with aliases for audit fields
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Response:
- Status code:
200
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'Children of the stars',
'metadata' : {
'schema': 'https://api.us.yaas.io/hybris/schema/v1/framefrog/mapAuditFields'
}
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj.body
Assign new Id of returned object to a variable.
id = comic_obj.body.id;
id
Retrieve a Document
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Response:
- Status code:
201
- Status code:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_obj.body
Nest audit fields
Request
- Method: PUT
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Query Parameters:
- patch:
true
- patch:
- Response:
- Status code:
200
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).put({
'metadata': {
'schema':'https://api.us.yaas.io/hybris/schema/v1/framefrog/nestAuditFields'
}
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {
'patch' : true
}
})
comic_obj.body
Retrieve a document with nested audit fields
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_obj.body
Perform a Projection to Limit a List of Returned Object's Fields or Attributes
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
Create objects
To simulate a projection, you must first create three sample objects as shown in this example.
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Response:
- Status code:
201
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'The Three Elders of Aran',
'price' : '15.99',
'cover' : 'hardcover'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj.body
To make calls simpler and code cleaner, assign Id of returned object to a variable.
id = comic_obj.body.id;
id
comic_obj2 = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'Child of the Stars',
'price' : '10',
'cover' : 'hardcover'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj2.body
id2 = comic_obj2.body.id;
id2
comic_obj3 = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'The Guardian of the Keys',
'price' : '15.99',
'cover' : 'paperback',
'condition' : 'good'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj3.body
id3 = comic_obj3.body.id;
id3
Retrieve a specific object with a projection on fields
In this example, you retrieve Thorgal comic with title and price attributes.
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Query parameters:
- fields:
title, price
- fields:
- Response:
- Status code:
200
- Status code:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {
'fields' : 'title, price'
}
})
get_obj.body
Get the number of objects with a projection on fields
In this example, you get Thorgal comics that have a title, price, and version.
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Query parameters:
- fields:
title, price, version
- fields:
- Response:
- Status code:
200
- Status code:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {
'fields' : 'title, price, version'
}
})
get_obj.body
Search for Objects and Sort Search Result
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
Create objects
To simulate a search, you must first create three sample objects as shown in this example.
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Response:
- Status code:
201
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'The Three Elders of Aran',
'price': 15.99,
'cover': 'hardcover'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj.body
comic_obj2 = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'Child of the Stars',
'price': 10,
'cover': 'hardcover'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj2.body
comic_obj3 = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'The Guardian of the Keys',
'price': 15.99,
'cover': 'paperback',
'condition' : 'good'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj3.body
Retrieve an object with a query on attributes
In this example, you search for a Thorgal comic using the following query:
- Cover type is hardcover.
- Price is between 10 and 20.
- Title is The Guardian of the Keys or The Three Elders of Aran or Child of the Stars.
- Added to the database after 2014-04-18.
- Search results sorted in ascending order.
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Query Parameters:
- q:
name:"Thorgal" cover:"hardcover" price:(>=10 AND <=20) title:in("The Guardian of the Keys","The Three Elders of Aran","Child of the Stars") createdAt:>=2014-04-18 - sort:
title:asc
- q:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {
'q' : 'name:Thorgal cover: hardcover price:(>=10 AND <=20) title:in("The Guardian of the Keys", "The Three Elders of Aran", "Child of the Stars") createdAt:>=2014-04-18',
'sort' : 'title:asc'
}
})
get_obj.body
SAP Hybris recommends that you create indexes for better search performance.
Retrieve an object with a query based on attribute presence
In this example, you search for a Thorgal comic with a condition attribute.
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Query Parameters:
- q:
name:"Thorgal" condition:exists
- q:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {
'q' : 'name:"Thorgal" condition:exists'
}
})
get_obj.body
- If you want to find an object that does not have a specific attribute, use the query term
missinginstead ofexists. If you want to find an object with an attribute that has the value
existsormissing, you must put these values in quotation marks:name:"exists".Basic search options
In this example, you search for a Thorgal comic with the following conditions:
The name of the comic series is Thorgal:
name:Thorgal- The cover type is hardcover:
cover:hardcover - The price is between 10 and 20 (greater than or equal to 10, less than or equal to 20):
price:(>=10+AND+<=20) - The title is The Guardian of the Keys, The Three Elders of Aran, or Child of the Stars:
title:in("The+Guardian+of+the+Keys","The+Three+Elders+of+Aran","Child+of+the+Stars") - The comic was added to the database on or after April 18, 2015 (2015-04-18):
createdAt:>=2015-04-18 There is an existing attribute that describes the physical condition of the comic:
condition:existsThis is how the query looks in a URI:
?q=name:"Thorgal" cover:"hardcover" price:(>=10+AND+<=20)+title:in("The+Guardian+of+the+Keys","The+Three+Elders+of+Aran","Child+of+the+Stars")+createdAt:>=2015-04-18+condition:exists
- The first two conditions point to the specific values of the attributes name and cover.
- The next condition, price, has a specified range of values defined by logical symbols of equality
=and inequality<,>. The range of values must be put inside the parentheses()with theANDoperator between the beginning and end values of the range. - The condition for title contains three different but specific values separated by commas and enclosed in parentheses. The Document service returns documents that match any of the included values.
- The next condition refers to a standard createdAt attribute in the Document service that uses date and time notation in an ISO standard format. In this case, it is a range of time defined by logical symbols of equality and inequality, but you can also use a specific date and time.
The last condition checks if there is an attribute describing the physical condition of the comic. It only checks whether the specified value exists. It does not check what the value of the attribute is. You can also search for missing attributes by replacing
existswithmissing.Count from a query
This example returns a total count of the number of objects in the collection.
Request
Method: HEAD
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Query Parameters:
- q:
name:"Thorgal" cover:"hardcover" price:(>=10 AND <=20) title:("The Guardian of the Keys","The Three Elders of Aran","Child of the Stars") createdAt:>=2014-04-18
- q:
count = documentService.tenant(tenant).client(client).data.type('comic').head(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {
'q' : 'name:"Thorgal" cover:"hardcover" price:(>=10 AND <=20) title:("The Guardian of the Keys","The Three Elders of Aran","Child of the Stars") createdAt:>=2014-04-18'
}
})
count.headers
Streaming big result sets
This example shows how you can stream large result sets when you query the /{tenant}/{client}/data/{type} endpoint without paging.
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- Required:
- Query parameters:
- fetchAll: A query parameter that fetches all of the records in a single request.
- Response:
- Status code:
200 - Transfer-encoding:
chunked
- Status code:
fetchAll query parameter is set to true, do not provide pageNumber and/or pageSize query parameters as this results in 400 Bad Request response from the Document service.fetchAll parameter set to true does not return totalCount (even if totalCount parameter was set to true in the request.) If you need a number of documents that are returned, you must handle this logic on your side.Sort Objects by Localized Attributes
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
The Document service supports sorting in ascending and descending order.
- Ascending (asc): Objects with localized attributes are listed after objects without such attributes or without localization on such attributes.
- Descending (desc): Objects with localized attributes are listed first.
Create objects
To simulate a search, you must first create three sample objects as shown in this example.
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Headers:
- Content-Language: Optional. To be provided only if the body of the request does not contain languages map.
- hybris-metaData:
title:localized
- Response:
- Status code:
201
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': {
'pl' : 'Miasto zaginionego boga',
'en' : 'City of the Lost God'
},
'price': 15.99,
'cover': 'hardcover'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metaData' : 'title:localized'
}
})
comic_obj.body
comic_obj2 = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': {
'pl' : 'Gwiezdne Dziecko',
'en' : 'Child of the stars'
},
'price': 10,
'cover': 'hardcover'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metaData' : 'title:localized'
}
})
comic_obj2.body
comic_obj3 = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': {
'pl' : 'Strażniczka kluczy',
'en' : 'The Guardian of the Keys'
},
'price': 15.99,
'cover': 'paperback'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metaData' : 'title:localized'
}
})
comic_obj3.body
To make calls simpler and code cleaner, assign Id of returned object to a variable.
id = comic_obj.body.id;
id
id2 = comic_obj2.body.id;
id2
id3 = comic_obj3.body.id;
id3
Retrieve objects sorted in descending order by localized attribute - without a metadata header
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Query Parameters:
- sort:
title.pl:desc
- sort:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {
'sort' : 'title.pl:desc'
}
})
get_obj.body
Retrieve objects sorted in ascending order by localized attribute - with a metadata header
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Headers:
- Accept-Language:
pl - hybris-metaData:
title:localized
- Accept-Language:
- Query Parameters:
- sort:
title:asc
- sort:
get_obj= documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'Accept-Language' : 'pl',
'hybris-metaData' : 'title:localized'
},
query: {
'sort' : `title:asc`
}
})
get_obj.body
Create an Index for Better Searching Performance
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create an API client for the Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
Create an index for two attributes
To create an ascending index, use 1 as the value. For a descending index, use -1.
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/indexes/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic.
- Required:
- Response:
- Status code: 201
index_obj = documentService.tenant(tenant).client(client).indexes.type('comic').post({
'keys': {
'name' : 1,
'cover' : -1
}
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
index_obj.body
429 response code from the Document service, send your request again at a later time. To learn more about index creation limitations, see the Considerations section of the Document service documentation.You can also use options in the body of your request to create, for instance an index with a unique name.
- Body:
{ "keys" : { "name" : 1, "cover" : -1 }, "options" : { "name" : "ComicIndx" } }
Retrieve all indexes to confirm that the index is on the list
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/indexes/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic.
- Required:
- Response:
- Status code: 200
get_obj = documentService.tenant(tenant).client(client).indexes.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_obj.body
Operate on Object with Localized Attributes
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
Create an object with one localized attribute with multiple languages
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Headers:
- Content-Language: Use this header to specify the language of the attribute value. Do not use this header if the body of your request contains a language map.
- hybris-metaData:
title:localized
- Response:
- Status code: 201
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': {
'en': 'The Archers',
'fr': 'Les Archers'
}
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metaData' : 'title:localized'
}
})
comic_obj.body
To make calls simpler and code cleaner, assign Id of returned object to a variable.
id = comic_obj.body.id;
id
Retrieve objects by localized attributes
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document. In this example, it is
comic.
- Required:
- Headers:
- Accept-Language:
fr - hybris-metaData:
title:localized
- Accept-Language:
- Response:
- Status code: 200
The response includes an object with the title attribute and its localized value.
get_obj = documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metaData' : 'title:localized',
'Accept-Language' : 'fr'
}
})
get_obj.body
- If an object does not have a localized title, it is returned with a default value.
- If an object has a localized title, but the desired language is not available, it is returned with a
nullvalue. - You can also have a fallback mechanism when getting a list of objects. For example, if you want to display an English title instead of a
nullvalue when a Polish title is not available , you must passpl,enin the request headerAccept-Languageto indicate Polish (pl) as a primary language and English (en) as a fallback language. This fallback accepts the desired languages with their weights, such aspl,en;q=0.8. The weight of the Polish language is 1.0 (implicit) and English is 0.8. The languages are separated by a comma (,), and the weight is supplied after a semicolon (;). For more information, see this list of HTTP header fields.
Update a localized attribute with an additional value
Request
- Method: PUT
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Headers:
- Content-Language:
pl - hybris-metaData:
title:localized
- Content-Language:
- Query Parameters:
- partial:
true
- partial:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).put({
'title': 'Łucznicy'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'hybris-metaData' : 'title:localized',
'Content-Language' : 'pl'
},
query: {
'patch' : true
}
})
comic_obj.body
Retrieve an object to verify that its title is available in three languages
To retrieve all values of localized attribute perform a simple GET request without header specifying the particular language.
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_obj.body
Get Aggregated Data
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
Create objects
To try the aggregation, we must first store some data. We start with creating three simple objects of type comic.
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Response:
- Status code:
201
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'The Three Elders of Aran',
'price': 16,
'cover': 'hardcover',
'reviews' : {
'number' : 12,
'score' : 8.7
}
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
}
})
comic_obj.body
comic_obj2 = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'Child of the stars',
'price': 14,
'cover': 'hardcover',
'reviews' : {
'number' : 10,
'score' : 9.1
}
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
}
})
comic_obj2.body
comic_obj3 = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'The Guardian of the Keys',
'price': 12.99,
'cover': 'paperback',
'condition' : 'good',
'reviews' : {
'number' : 18,
'score' : 8.9
}
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
}
})
comic_obj3.body
Retrieve aggregated data on a specific attribute
For the created data we would like to get the average price, the average reviews' score and the sum of total reviews. Additionally we would like to know the number of objects. We want all of these for comics in hardcover only, so we add a proper query.
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/aggr/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Query Parameters:
- avg:
price,reviews.score - count:
true - sum:
reviews.number - q:
cover:hardcover
- avg:
get_obj = documentService.tenant(tenant).client(client).aggr.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {
'avg' : 'price,reviews.score',
'sum' : 'reviews.number',
'count' : 'true',
'q' : 'cover:hardcover'
}
})
get_obj.body
Perform Versioning with Optimistic Locking
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
Create an object
To simulate optimistic locking, you must first create a sample object.
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Response:
- Status code:
201
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
'name': 'Thorgal',
'title': 'Child of the Moon',
"price": 15.99,
"cover": "hardcover"
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
}
})
comic_obj.body
To make calls simpler and code cleaner, assign Id of returned object to a variable.
id = comic_obj.body.id;
id
Retrieve the object
In this example, two employees get the same object using the GET method.
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Response:
- Status code:
200
- Status code:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_obj.body
Add a new value for an attribute
Both employees try to change the title from "Child of the Moon" to "Child of the Star" using the PUT method.
Request
- Method: PUT
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Query parameters:
- partial:
true - version:
1
- partial:
First response
This is the response that the first employee receives:
- Status code:
200 - Body:
- Content type:
application/jsonjson { "code": "200", "status": "200", "message": "Operation succeeded" }
- Content type:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).put({
'title' : 'Child of the Star'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {partial: true,
version: 1}
})
comic_obj.body
Second response
This is the response that the second employee receives.
- Status code:
409 - Body:
- Content type:
application/json
{ "status": "409", "message": "Optimistic locking failure: can't find object with given version: 1", "code": 409 }
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).put({
'title' : 'Child of the Star'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {partial: true,
version: 1}
})
comic_obj.body
Retrieve the object after changes
The employee that receives the error code of 409 must get the object again with the new properties.
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object. Response: Status code:
200
- Required:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_obj.body
Delete the object
In this example, an employee want to delete version 1 of the document which is updated by another employee to version 2.
Request
- Method: DELETE
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Query Parameters:
- version:
2
- version:
Response
- Status code:
409 - Body:
- Content type:
application/json{ "status": "409", "message": "Optimistic locking failure: can't find object with given version: 1", "code": 409 }
- Content type:
remove = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).delete(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken
},
query: {version: 1}
})
Perform a Partial Update on Multiple Objects
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
Create objects
To simulate a bulk update, you must first create three sample objects as shown in this example.
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
"name": "Thorgal",
"title": "The Three Elders of Aran",
"price": 15.99,
"cover": "hardcover"
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj.body
comic_obj2 = documentService.tenant(tenant).client(client).data.type('comic').post({
"name": "Thorgal",
"title": "Child of the Stars",
"price": 10,
"cover": "hardcover"
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj2.body
comic_obj3 = documentService.tenant(tenant).client(client).data.type('comic').post({
"name": "Thorgal",
"title": "The Guardian of the Keys",
"price": 15.99,
"cover": "paperback",
"condition": "good"
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj3.body
Update multiple objects
Request
- Method: PUT
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
Query parameters:
- q:
price:15.99
- q:
Response:
- Status code:
200
- Status code:
update = documentService.tenant(tenant).client(client).data.type('comic').put({
'rarity': 'uncommon'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {
'q' : 'price:15.99'
}
})
update.body
Retrieve information about updated objects
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Query Parameters:
- q:
rarity:uncommon
- q:
- Response:
- Status code:
200
- Status code:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
},
query: {
'q' : "rarity:uncommon"
}
})
get_obj.body
Perform Bulk Operations on Tags
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
Create objects
To simulate a bulk update, you must first create three sample objects as shown in this example.
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
"name": "Thorgal",
"title": "The Three Elders of Aran",
"price": 15.99,
"cover": "hardcover"
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj.body
comic_obj2 = documentService.tenant(tenant).client(client).data.type('comic').post({
"name": "Thorgal",
"title": "Child of the Stars",
"price": 10,
"cover": "hardcover"
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj2.body
comic_obj3 = documentService.tenant(tenant).client(client).data.type('comic').post({
"name": "Thorgal",
"title": "The Guardian of the Keys",
"price": 15.99,
"cover": "paperback",
"condition": "good"
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj3.body
Create tags for all objects of a specific type
You can simultaneously add tags to multiple objects of the same type.
- Tags must be text values.
- Any duplicates are removed.
- You can narrow the object list by adding a simple query.
- This operation creates an array of tags. You can have more than one array of tags with different names.
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/tags/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Query Parameters:
- q:
name: Thorgal - tags:
genre: fantasy,adventure
- q:
- Response:
- Status code:
200
- Status code:
comic_obj = documentService.tenant(tenant).client(client).tags.type('comic').post(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
},
query: {q : 'name:Thorgal',
tags : 'genre:fantasy,adventure'}
})
comic_obj.body
Get all objects of a specific type to confirm tags addition
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Headers:
- Optional:
- Accept-Encoding: Set the header to the
gzipvalue to receive a compressed response, thus reducing the response time and bandwidth used. GZIP is the only supported format for content encoding.
- Accept-Encoding: Set the header to the
- Optional:
- Query Parameters:
- q:
name: Thorgal - Response:
- Status code:
200
get_obj = documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'Accept-Encoding' : 'gzip',
},
query: {q : 'name:Thorgal'}
})
get_obj.body
Remove tags for all objects of a specific type
This operation contains an additional query parameter called removeEmpty that specifies whether or not to remove the empty array when the tags are removed. If this parameter is set to false, the tags are deleted from the array, but the empty array still exists.
Request
- Method: DELETE
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/tags/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Query Parameters:
- q:
name: Thorgal - removeEmpty:
false - tags:
genre: fantasy,adventure
- q:
- Response:
- Status code:
204
- Status code:
remove = documentService.tenant(tenant).client(client).tags.type('comic').delete(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
},
query: {q : 'name:Thorgal',
removeEmpty : false,
tags : 'genre:fantasy,adventure'}
})
Get all objects of a specific type to confirm tags deletion
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Query Parameters:
- q:
name: Thorgal - Response:
- Status code:
200
get_obj = documentService.tenant(tenant).client(client).data.type('comic').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json',
'Accept-Encoding' : 'gzip',
},
query: {q : 'name:Thorgal',
tags : 'genre:fantasy,adventure'}
})
get_obj.body
Nested objects
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
Create an object with a nested array object
In this example, you want to sell second-hand comics. This means that you can have the same comics from different publishers. To do this, you want to have an object with an array that keeps a list of publishers.
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Response:
- Status code:
201
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
"name": "Thorgal",
"title": "Child of the Stars",
"publishers": [
{"publisher":"Le Lombard"},
{"publisher":"Orbita"}
]
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj.body
To make calls simpler and code cleaner, assign Id of returned object to a variable.
id = comic_obj.body.id;
id
Create an additional array record
In this example, you want to update your nested array object with an additional publisher. You must refer explicitly to an array name. It is the name of the attribute that contains an array. Optionally, you can use a PUT method on a necessary record in the array with a specific index. If the specified index does not exist, null values are added to ensure the given index. For example, if you specify an index of 3 and the array has less than three elements, null values are added.
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId}/{attributeName} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- attributeName: The name of an attribute.
- Required:
- Response:
- Status code:
200
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).attributeName('publishers').post({
'publisher' : 'Korona'
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
comic_obj.body
The new publisher is added at the end of the array.
Retrieve only specific array values
To verify that the new publisher is added, you must get that specific publisher in the response. You know it is the third publisher, so you need to refer to a specific array index.
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId}/{attributeName}/{index} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- attributeName: The name of an attribute.
- index: The specific array index, such as
2.
- Required:
- Response:
- Status code:
200
- Status code:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).attributeName('publishers').index('2').get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_obj.body
Remove specific array values
You no longer need the first publisher, so you can delete it. Please note, that removing array values results in null value being inserted inside the array at a given position.
Request
- Method: DELETE
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId}/{attributeName}/{index} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- attributeName: The name of an attribute.
- index: The specific array index, such as
0.
- Required:
- Response:
- Status code:
204
- Status code:
remove = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).attributeName('publishers').index('0').delete(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
Retrieve the entire object to verify that one record from the array is missing
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Response:
- Status code:
200
- Status code:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-type' : 'application/json'
}
})
get_obj.body
Nested Attributes
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
You can create documents with nested attributes using a schema or metadata.
Schema
There is a schema used in this tutorial. You can create schema based on this example and publish it in the Schema service or on a server of your choice:
Create a new document with nested attributes using a schema
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Headers:
- Content-Language:
en_US
- Content-Language:
- Response:
- Status code:
201
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
"name": "Thorgal",
"original_release" : "1985-05-13T12:00:00.000Z",
"title": "The Archers",
"available": {
"published": "1989-05-13T12:00:00.000Z",
"title": "The Archers"
},
"metadata" : {
"schema": "https://api.us.yaas.io/hybris/schema/v1/framefrog/comicSchema_v2.json"
}}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-Type' : 'application/json',
'Content-Language' : 'en_US'
}
})
comic_obj.body
To make calls simpler and code cleaner, assign Id of returned object to a variable.
id = comic_obj.body.id;
id
Retrieve an object created with a schema
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Headers:
- hybris-languages:
*
- hybris-languages:
- Response:
- Status code:
200
- Status code:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-Type' : 'application/json',
'hybris-languages' : '*'
}
})
get_obj.body
title as localized by "$ref": "https://pattern.yaas.io/v2/schema-localized.json". In effect, all titles have the localized attribute set as in the Content-Language header or body of the request.Create a new document with nested attributes using metadata
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Headers:
- Content-Language:
en_US - hybris-metaData:
title:localized;available.title:localized;original_release:date;available.published:date
- Content-Language:
- Response:
- Status code:
201
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
"name": "Thorgal",
"original_release": "1985-05-13T12:00:00.000Z",
"title": "The Archers",
"available": {
"published": "1989-05-13T12:00:00.000Z",
"title": "The Archers"
}
},
{
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-Type' : 'application/json',
'Content-Language' : 'en_US',
'hybris-metaData' : 'title:localized;available.title:localized;original_release:date;available.published:date'
}
})
comic_obj.body
To make calls simpler and code cleaner, assign Id of returned object to a variable.
id = comic_obj.body.id;
id
Retrieve an object created with a metadata
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Headers:
- hybris-languages: To retrieve your localized attributes in all stored language versions use
*parameter.
- hybris-languages: To retrieve your localized attributes in all stored language versions use
- Response:
- Status code:
200
- Status code:
get_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-Type' : 'application/json',
'hybris-languages' : '*'
}
})
get_obj.body
title fields as localized in the hybris-metaData header: title:localized;available.title:localizedOperate on Mixins
Get all your variables in one place
The following variables are used within this tutorial:
tenant = {{projectId}};
client = {{clientName}};
AccessToken = {{token}};
Create API client for Document service
API.createClient('documentService',
'/services/document/v1/api.raml');
This tutorial explains how to provide additional product attributes using mixins.
The tutorial is divided into two subsections:
- The first example uses an existing schema that has been published on a server and placed in
metadata. - The second example presents how to create a mixin with an inline schema.
Schemas
There are two schemas used in this tutorial. You can create schemas based on these examples and publish them on a server of your choice or in the Schema service:
Use existing schemas
Create an object with a schema
Use a schema to create an object with localized title and am original_price of type amount.
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Required:
- Headers:
- Content-Language: Use this header to specify the language of the attribute value. Do not use this header if the body of your request contains a language map.
- Response:
- Status code:
201
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
"name": "Thorgal",
"title": {
"en": "The Archers",
"fr": "Les Archers"
},
"original_price": {
"usd": 19.99,
"eur": 15.99
},
"metadata": {
"schema" : "https://api.us.yaas.io/hybris/schema/v1/framefrog/comicSchema_v5.json"
}}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-Type' : 'application/json'
}
})
To make calls simpler and code cleaner, assign Id of returned object to a variable.
id = comic_obj.body.id;
Update an object with a simple mixin
Update an object by adding a simple mixin that defines the new field CollectorsValue of type amount.
Request
- Method: PUT
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Query Parameters:
- partial:
true
- partial:
- Response:
- Status code:
200
- Status code:
documentService.tenant(tenant).client(client).data.type('comic').dataId(id).put({
"mixins" : {
"collectors_info" : {
"CollectorsValue": {
"usd": 30.99,
"eur": 23.99
}
}
},
"metadata" : {
"schema" : "https://api.us.yaas.io/hybris/schema/v1/framefrog/comicSchema_v5.json",
"mixins" : {
"collectors_info" : "https://api.us.yaas.io/hybris/schema/v1/framefrog/comicCollectorValue_v1.json"
}
}
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-Type' : 'application/json'
},
query: {
'partial' : 'true'
}
})
Get an object with a simple mixin
When reading the object all the attributes will be returned according to their types defined in both schema and mixin.
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Headers:
- Accept-Language:
fr - hybris-currencies:
usd
- Accept-Language:
- Response:
- Status code:
201
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Accept-Language' : 'fr',
'hybris-currencies' : 'usd'
}
})
Use an inline mixin
Create an object with a schema
Request
- Method: POST
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- Headers:
- Content-Language: Use this header to specify the language of the attribute value. Do not use this header if the body of your request contains a language map.
- Response:
- Status code:
201
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').post({
"name": "Thorgal",
"title": {
"en": "The Archers",
"fr": "Les Archers"
},
"original_price": {
"usd": 19.99,
"eur": 15.99
},
"metadata": {
"schema" : "https://api.us.yaas.io/hybris/schema/v1/framefrog/comicSchema_v5.json"
}}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-Type' : 'application/json'
}
})
Update an object with an inline mixin
Request
- Method: PUT
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Query Parameters:
- partial:
true
- partial:
- Response:
- Status code:
200
- Status code:
documentService.tenant(tenant).client(client).data.type('comic').dataId(id).put({
"mixins":
{
"collectors_info":
{
"CollectorsValue": {
"usd": 35.99,
"eur": 26.99
}
}
},
"metadata":
{
"schema": "https://api.us.yaas.io/hybris/schema/v1/framefrog/comicSchema_v5.json",
"mixins":
{
"collectors_info":
{
"$schema" : "http://json-schema.org/draft-04/schema#",
"type" : "object",
"properties":
{
"CollectorsValue" :
{
"$ref": "https://api.us.yaas.io/hybris/schema/v1/framefrog/comicCollectorValue_v1.json"
}
}
}
}
}
}, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Content-Type' : 'application/json'
},
query: {
'partial' : 'true'
}
})
To make calls simpler and code cleaner, assign Id of returned object to a variable.
id = comic_obj.body.id;
Get an object with an inline mixin
When reading the object all the attributes will be returned according to their types defined in both schema and inline mixin.
Request
- Method: GET
- Request URL:
https://api.beta.yaas.io/hybris/document/v1/{tenant}/{client}/data/{type}/{dataId} - URI parameters:
- Required:
- tenant: The project that requests this resource.
- client: The ID of the client.
- type: The type attribute of the document.
- dataId: The ID of an object.
- Required:
- Headers:
- Accept-Language:
fr - hybris-currencies:
usd
- Accept-Language:
- Response:
- Status code:
201
- Status code:
comic_obj = documentService.tenant(tenant).client(client).data.type('comic').dataId(id).get(null, {
headers: {
'Authorization': 'Bearer ' + AccessToken,
'Accept-Language' : 'fr',
'hybris-currencies' : 'usd'
}
})
Security
The Document service is a container for your Documents. You control the data stored in the Document service, and only you know whether the document contains personal data and which data subject the data relates to. Therefore, to meet the data privacy requirements you must map documents containing personal data with corresponding data subjects, and implement a logic to serve data subject's requests related to its personal data, such as requests for information or deletion. To meet these goals, follow instructions provided in the Developer Guidelines for Data Privacy.
Glossary
| Term | Description |
|---|---|
| CRUD | It stands for basic operations: Create, Read, Update and Delete. |
| document | A data object created in a database that contains a set of information provided as a JSON schema when created. Identified by its ID. |
| ETag (entity tag) | A header included in a GET response that contains a unique hash for the payload in order to validate the cache. This mechanism is used for cache validation by comparing two entities from the same requested resource. |
| index | A value that identifies the data item. Indexes locate data items within a data array or table, therefore using indexes improves search performance. |
| mixin | A mixin is a simple schema that contains additional document attributes. |
| schema | A human- and machine-readable description of a JSON document expressed in terms of constraints on the fields and structure. |
| storage | A dedicated hardware instance shared by the group of clients. |
| tag | Keyword or term assigned to the document. You can use tags to describe documents for a better, more intuitive search experience. |
If you find any information that is unclear or incorrect, please let us know so that we can improve the Dev Portal content.
Use our private help channel. Receive updates over email and contact our specialists directly.
If you need more information about this topic, visit hybris Experts to post your own question and interact with our community and experts.